机器学习-0-通识与基础
机器学习概述
机器学习:Machine Learning ,是让计算机自己从数据中学习规律,并根据所得到的规律对未来的数据进行预测。请注意,这里说的规律,并不是指函数本身,而是函数本身(包含参数)或 仅参数。
机器学习包含了聚类、分类、决策树、贝叶斯、神经网络、深度学习很多算法。这其中,神经网络与深度学习之前的方法中,由人设计函数本身,但人并不知道函数中的参数是多少,由机器学习参数;而神经网络与深度学习的厉害之处在于,它不需要人手工设计函数是什么,直接同时学习出函数本身与参数。
这有什么好处?人很难设计出一种非常复杂的函数,因为人的理解力毕竟是有限的。
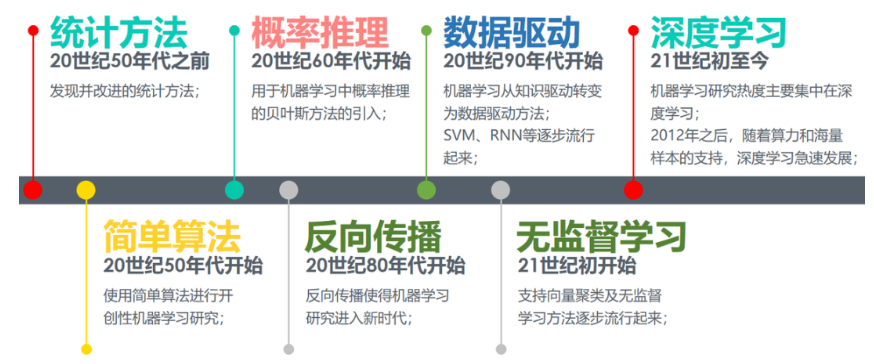
发展历史
- 60年代中到70年代末的发展几乎停滞。
- 80年代使用神经网络反向传播(BP)算法训练的多参数线性规划(MLP)理念的提出将机器学习带入复兴时期。(第一次浪潮)
- 90年代提出的“决策树”(ID3算法),再到后来的支持向量机(SVM)算法,将机器学习从知识驱动转变为数据驱动的思路。(第二次浪潮)
- 21世纪初Hinton提出深度学习(Deep Learning),使得机器学习研究又从低迷进入蓬勃发展期。(第三次浪潮)
分类
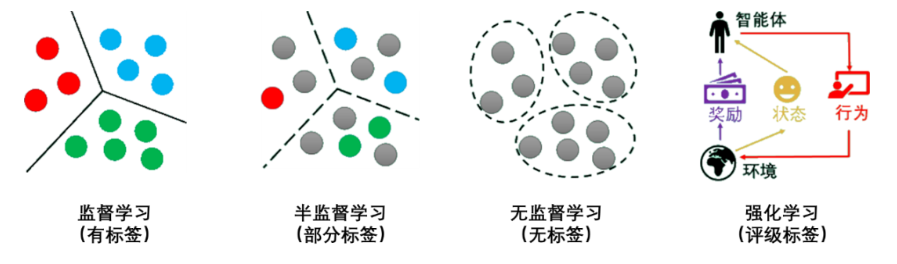
按照学习模式的不同,可以分为:
- 监督学习
- 半监督学习
- 无监督学习
- 强化学习
监督学习
Supervised Learning ,从有标签训练数据中学习模型,然后对于某个给定的新数据预测标签。
有两大类任务:回归与分类。
- 回归:预测 连续的、具体的数值。常见算法:线性回归、Robust回归、Ridge回归、LASSO回归、Elastic Net、多项式回归、SGD(随机梯度下降)、多层感知机、随机森林回归、SVM(支持向量机)、回归树、K-NN、Adaboost、神经网络等。
- 分类:预测 不连续的、离散的数值。常见算法:朴素贝叶斯、决策树、SVM(支持向量机)、逻辑回归、KNN、A大boost、神经网络等。
半监督学习
Semi-Supervised Learning ,利用少量标注数据与大量无标注数据进行学习的模型。
主要可能有两大类任务:
- 分类
- 检测
半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
常见的半监督学习算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch等。
后续看看这个文章 https://mp.weixin.qq.com/s/kvqic9Qpvnz0BDvrIViZlg
无监督学习
Unsupervised Learning,利用未经过外部标记标签的数据进行训练。
主要任务:
- 关联性分析
- 聚类
- 降维
主要的算法有:稀疏自编码(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等。
一般,我个人的看法是将自监督学习看作是一种特殊的无监督学习,区别在于它首先对数据的一部分进行预测,自行生成训练目标(伪标签)。
强化学习
强化学习并没有利用样本数据进行训练,但类似于监督学习,需要与环境(或人)不断交互,在试错中学习。
在强化学习中,有两个可以进行交互的对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
主要任务:机器人避障、棋牌类游戏、广告和推荐等应用场景中。
如何应用机器学习?
- 将现实问题抽象为数学问题。如问题“给定图片判断是猫还是狗”归结为“二分类”问题
- 数据准备,或下载数据集,或自己标注、整理数据集。将数据集划分为 训练集(60%)、验证集(20%)、测试集(20%)
- 选择模型:根据 数据类型、样本量、问题本身的性质 综合考虑。
- 选择合适的损失函数与优化策略、模型训练与评估
- 应用训练好的模型、预测结果。
参考文献
[1] 数据派THU-公众号