需要看的东西
这个面经 网上面经 数字图像处理经典方法 自己的项目 机器学习经典方法
目标检测 RCNN fast RCNN YOLO
纸质版面经
过拟合的处理:数据增广、早停、dropout、正则化、集成模型、ReLU激活函数
欠拟合的处理方法:模型复杂化、增加特征、调整参数与超参数、增加训练数据一般是没用的、降低正则化约束
梯度消失:两种说法:一般是选了不合适的激活函数 1.
靠近输出层的梯度大,收敛快,靠近输入层的梯度小,更新慢,几乎和初始一样。(从深度神经网络角度看)
2. 连乘小数导致的。(从激活函数角度看)
硬饱和性与软饱和性:硬是倒数为0,软是接近0.
tanh -1,1
一般用于二元分类的隐含层(均值为0,收敛速度更快),sigmoid一般用于预测概率或者输出层。
ReLU
修正线性单元单元,计算速度更快,单侧改善梯度消失。缺点是有可能造成神经元的死亡。
Softmax 多分类头的激活函数,零点不可微,死亡神经元
梯度爆炸:权重初始化比值过大
解决方法: 梯度剪切、权重正则化(防止W过大)、其他激活函数,BN层
L1的作用是为了矩阵稀疏化。假设的是模型的参数取值满足拉普拉斯分布。
L2的作用是为了使模型更平滑,得到更好的泛化能力。假设的是参数是满足高斯分布。
梯度消失解决办法
预训练+微调(最开始是无监督逐层方法,现在不用了)
梯度剪切(爆炸),正则化(爆炸,因为爆炸发生时,权值的范数会变得很大)
使用Relu 系列的激活函数
BN 通过对每一层的输出做 scale 和 shift
,是的将每层神经网络神经元的输入值的分布强行拉回到接近均值为0方差为1的标准正太分布,进而使得输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数的较大变化,加快收敛
残差结构:跳变链接(短路可以无损传播提梯度,残差梯度需要经过层,有1在不会让梯度消失)
LSTM 通过门结构记住前几次训练时的残留记忆。
权值共享:CNN卷积核参数共享
微调: 1. 因为靠近输出的是更细节的特征 2.
用于微调的模型参数量大,所以需要防范过拟合,冻结
dropout:防止过拟合,前向时让某个神经元的激活值以概率P停止工作,
类似于 bagging(减少方差),boosting(减少偏差bias)。模型推理不需要dpo
输入曾概率为0.8 隐藏层为0.5
Adam:用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,在经过偏置的矫正后,每一次迭代的学习率都范围稳定,参数变动比较平稳
SGD:每一次迭代计算数据集的minibatch的梯度,然后对参数进行更新
Adam 快速优化,SGD精准优化
动量:累加了历史梯度更新方向,加强与历史趋势相同的,抑制与历史梯度相反的,限制了梯度更新的随机性。
batch size 增大,方向更精准,但是每个批次处理时间拉长 变小,欠拟合
iteration:一个batch训练一次 epoch:所有batch 训练一轮
学习率:小,收敛慢,也有可能局部最优 大:震荡 爆炸,无法收敛
SGD:一阶导数 牛顿法:二阶导数,慢
拟牛顿法:凸问题,但是神经网络大部分是非凸的
小模型 精度:蒸馏 AutoML
CNN:输入 卷积 激活 池化(降采样) 全连接
1*1
卷积的作用:改变通道数量,减小参数两,用于语义分割等密集预测,等价于FC
CNN输出的大小:o=(W-K+2P)/S+1,K是过滤器尺寸,P是填充,S是步幅。
卷积层参数量=(卷积核尺寸前一层的特征图的通道数) 当前层卷积核数量=当前层卷积核数量
参数量的计算????figure 的大小计算???
空洞卷积:扩张卷积,参数梁不变的情况下,将感受野扩大。
减小CNN参数量:堆叠小卷积,分离卷积,1*1卷积,卷积之前使用池化。
反卷积,转置卷积:上采样
Res 系列:
Res发现前馈与反馈可以直接传输,ResNet2给每一层都加上了BN
网上面经
自己的项目
损失函数
KL散度 交叉熵
熵来计算“在确保信息传递过程不失真的情况下,传递信息所需要的最小编码大小”。
在二分类问题中,E=- [y * log(p) + (1 - y) * log(1 -
p)],其中y是样本的真实标记,p是模型的预测概率。 在多分类问题中,E=- Σ
[y_i *
log(p_i)],y_i和p_i对应第i个类别的真实标记与预测概率,n是类别个数。
KL散度不符合对称性 所以不能称之为距离 D_KL(p||q)=p(x_i)*log(p/q)
扩散模型
思路:构建数据对-需要后验概率-不知道-知道带 x_0
的后验概率-那我们来最小化两个高斯分布-协方差是人设定的不用管-简化为最小化均值之间的距离-均值之间只有误差不知道,所以学习误差
训练过程: 1. 数据集随机采样图像 2. 随机采样时间步 3.
前向扩散添加噪声 4. 模型根据假造图像与时间步预测噪声 5.
计算预测噪声与实际噪声之间的误差 使用均方误差作为损失函数
Diffusion
Model是一种受到非平衡热力学启发的生成模型,其核心思想是通过模拟扩散过程来逐步添加噪声到数据中,并随后学习反转这个过程以从噪声中构建出所需的数据样本。
Denoising Diffusion Probabilistic
Model(DDPM,去噪扩散概率模型)是一种参数化的马尔可夫链模型,使用变分推断进行训练,以在有限时间内生成与数据匹配的样本。
Latent Diffusion
Model(LDM,潜在扩散模型)是一种结合了扩散模型和变分自动编码器(VAE)优势的生成模型,它能够在保持对生成过程控制的同时,产生高度现实和多样化的产出。
Stable Diffusion是一个基于Latent Diffusion
Model(LDM)的文图生成(text-to-image)模型,其核心在于在潜空间中高效处理数据。LDM是对原始Diffusion
Model的改进,通过引入Autoencoder来降低计算复杂度并提高图像生成效率。
编解码器结构
GAN
框架的训练是以D最大化为训练样本和G的样本分配正确标签的概率。同时训练G以最小化log(1
- D(G(z)))。换句话说,D和G进行如下的两人极大极小博弈,其值函数为V
(G,D)
DCGAN DCGAN(deep convolutional generative adversarial
networks)采用深度卷积的生成对抗网络。 改进
1.取消Pooling层,改用加入stride的卷积代替。同时用卷积替代了全连接层。 2.
在D和G网络中均加入BN层。 3.
G网络使用ReLU作为激活函数,最后一层使用tanh。 4.
D网络中使用LeakyReLU作为激活函数 5. 使用adam优化器训练
WGAN WGAN使用了新的距离定义 Wasserstein
Distance(推土机距离),在理论上给出了GAN训练不稳定的原因,即交叉熵(JS散度)不适合衡量具有不相交部分的分布之间的距离,转而使用wassertein距离去衡量生成数据分布和真实数据分布之间的距离,理论上解决了训练不稳定的问题。
Wasserstein距离又叫Earth Mover's Distance(EMD,推土机距离),参考:
几个常用的计算两个概率分布之间距离的方法以及python实现
WGAN的提升 1.
解决了GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度; 2.
几乎解决了mode collapse(模式崩溃)问题,保证生成样本的多样性; 3.
提供了具有意义的价值函数,可以分别判断判别器和生成器是否已经收敛。(原始GAN中如果D的效果不好,我们不知道是G生成的好,还是D判别的不好)
WGAN的改进 1. 去掉最后一层的sigmoid 2. 生成器和判别器的loss不取log 3.
限制更新后的权重的绝对值到一定范围内 4.
使用RMSprop或SGD优化,不建议使用基于动量或Adam的优化算法
https://mp.weixin.qq.com/s/IbuPfYy0baqUKq8WcsFHPw
FGSM PGD
想让攻击更加有效,导致模型分类错误,也就是使损失函数的值变大。正常训练模型时,输入x是固定的,标签y也是固定的,通过训练调整分类模型的参数w,使损失函数逐
渐变小。
而梯度攻击的分类模型参数w不变(分类逻辑不变),y也固定不变,若希望损失函数值变大,就只能修改输入。下面就来看看如何利用梯度方法修改输入数据。
https://mp.weixin.qq.com/s/rPCuDAYD34SSv9qPVutsNg
FGSM全称是Fast Gradient Sign
Method快速梯度下降法。其原理是求模型误差函数对输入的导数,然后用符号函数得到其梯度方向,并乘以一个步长ε,将得到的“扰动”加在原来的输入数据之上就得到了攻击样本。
FGSM从始至终只做了一次修改,改动的大小依赖步长ε,如果步长太大,则原数据被改得面目全非,如果改动太小又无法骗过模型。一般做干扰的目的是保持数据原始的性质,只为骗过模型,而非完全替换数据。迭代修改的方法PGD,每次进行少量修改,扰动多次
迁移学习
迁移学习涉及到权重加载、参数冻结和参数微调。权重加载有个值得关注的点——因为分类问题的不同,全连接层的维数需要修改。
ViT
CAM
类激活图
一般在最后一层卷积层的地方N特征图乘权重叠加,上采样得到与原图一样大的图像,反应越大代表这个地方越重要。
蒙特卡洛
实体纹理与图像纹理
非极大化抑制 NMS
IOU阈值保留一个对象的最佳候选框,因为会产生大量候选框,相互之间重叠度很高,需要保留最佳的。
根据置信度得分进行排序选择置信度最高的边界框添加到最终输出列表中,将其从边界框列表中删除计算所有边界框的面积计算置信度最高的边界框与其它候选框的IoU。删除IoU大于阈值的边界框重复上述过程,直至边界框列表为空。
每次选置信度最高的,计算其他与它的IOU,阈值大过的删除。
目标检测
两阶段
RCNN
区域提议(选择性搜索,图像分割为超像素,自底向上合并(颜色、纹理、尺寸、填充)),区域大小调整一致,提取特征(预训练的CNN
如 alexnet),SVM分类每个区域,使用线性回归调整候选区域的边界。
优点:预训练+提高精度 缺点:计算成本高,存储量大
fast rcnn: 引入ROI_pooling(划分ROI为需要的大小,每一格子里面做max
pooling),使得对任意的大小的候选区域特征能直接处理
引入多任务loss,联合训练位置损失和类别损失,将原本的分阶段训练变为一次训练,大大减小了模型的训练的复杂度
池化后的特征进行展平送入全连接,最后利用一个分类头和回归头分别得到类别概率和位置偏移
各类指标计算
图像
https://mp.weixin.qq.com/s/zk644RQrwT9ZY6rzcUpvRg
IoU 交并比 实际边框与预测边框的交叠程度
TP iou>阈值 0.5 FP iou<=阈值 FN 没有检测到的GT数量 TN用不到
precision 查准率 TP/(TP+FP) 精确率 Recall 查全率 TP/(TP+FN)
PR 曲线 准召曲线 AP 某一类曲线下的面积
mAP 所有类别的平均值 map.5 表示iou阈值为0.5 map:.95表示到为
0.5-0.95
NLP
https://mp.weixin.qq.com/s/NQIy0XnFNraWpYwFpaYhbg
acc=TP+TN/全 准确率
F1 score 精确率与召回率的调和平均值
MRR 只关注第一个相关项在哪里 倒数
Hit Rate top k 在n次测试中,Σ1(前k中有一个相关项目)/n
NDCG 归一化折损累积收益
CG
累计收益,只考虑相关性,没考虑位置,是所有结果相关性分数的综合。CGk的大小只能表现出Top
K个结果数的好坏,并不能表现出排序的好坏。为了能够衡量出排序的好坏,就有了下文的DCG。
DCG,排名越靠前,价值越高 NDCG 归一化的DCG,不同条件推荐的数量不同,CG
DCG是累计值,无法比较。 NDCG=DCG/IDCG
IDCG=label按照最佳排序方法得到的DCG
AUC(当推荐数量确定时,使用Precision@K和Recall@K ,否则使用P-R或ROC曲线。正样本被预测成正样本的概率大于负样本被预测成正样本的概率的概率,不关心内部排序)
ROC 当推荐数量确定时,使用Precision@K和Recall@K ,否则使用P-R或ROC曲线
数字图像处理
腐蚀和膨胀
插值方法:线性、双线性、最邻近、双三次、三次线性卷积
过拟合是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。
抑制过拟合的方法: (1)数据处理:清洗数据、减少特征维度、类别平衡。
(2)辅助分类节点:在Google Inception
V1中,采用了辅助分类节点的策略,即将中间某一层的输出用作分类,并按一个较小的权重加到最终的分类结果中,这样相当于做了模型的融合,同时给网络增加了反向传播的梯度信号,提供了额外的正则化的思想。
(3)正则化:获取更多数据:从数据源获得更多数据,或数据增强。
欠拟合:
现象:训练的模型在训练集上面的表现很差,在验证集上面的表现也很差。
原因:模型发生欠拟合的最本质原因是“训练的模型太简单,最通用的特征模型都没有学习到”
(1)做特征工程,添加更多的特征项。即提供的特征不能表示出那个需要的函数。
(2)减少正则化参数。即使得模型复杂一些。 (3)使用更深或者更宽的模型。
(4)使用集成方法。融合几个具有差异的弱模型,使其成为一个强模型。
卷积层的特点是局部感知、参数共享(减少计算量)和多核卷积。
边缘检测算子
边缘提取算子: 一阶导数:sobel、reberts prewitt 算子
二阶边缘导数算子:laplacian算子 噪声敏感
其他 canny 算子 12.Canny边缘检测的流程。
(1)图像降噪。梯度算子可以用于增强图像,本质上是通过增强边缘轮廓来实现的。但是,它们受噪声的影响很大。那么,我们第一步就是想到要先去除噪声,因为噪声就是灰度变化很大的地方,所以容易被识别为伪边缘。
(2)计算图像梯度,得到可能的边缘。计算图像梯度能够得到图像的边缘,因为梯度是灰度变化明显的地方,而边缘也是灰度变化明显的地方。这一步只能得到可能的边缘,因为灰度变化的地方可能是边缘,也可能不是边缘。这一步就有了所有可能是边缘的集合。
(3)非极大值抑制。通常灰度变化的地方都比较集中,将局部范围内的梯度方向上,回答变化量大的保留下来,其他的不保留,这样可以剔除掉一大部分的点。将有多个像素宽的边缘编程一个单像素宽的边缘,将“胖边缘”变成“瘦边缘”。
(4)双阈值筛选。通过非极大值抑制后,仍然有很多的可能边缘点,进一步设置一个双阈值,即低阈值(low),高阈值(high)。灰度变化大于high的,设置为强边缘像素,低于low的,剔除。在low和high之间的设置为弱边缘。进一步判断,如果其领域内有强边缘像素,保留,如果没有,剔除。
图像增强(image
augmentation)指通过剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换
高斯滤波器是一种线性滤波器,能够有效的抑制噪声,平滑图像。其作用原理和均值滤波器类似,都是取滤波器窗口内的像素的均值作为输出。其窗口模板的系数和均值滤波器不同,均值滤波器的模板系数都是相同的为1;而高斯滤波器的模板系数,则随着距离模板中心的增大而系数减小。所以,高斯滤波器相比于均值滤波器对图像个模糊程度较小。
将图像空间转变为参数空间
Hough变换的基本原理在于利用点与线的对偶性,将原始图像空间的给定的曲线通过曲线表达形式变为参数空间的一个点。这样就把原始图像中给定曲线的检测问题转化为寻找参数空间中的峰值问题。也即把检测整体特性转化为检测局部特性。比如直线、椭圆、圆、弧线等。
高斯噪声:概率密度服从正态分布,分布在每个点上,不能用中值滤波,需要使用均值
椒盐噪声:赋值近似,随机分布,有污染也有干净,均值不为0,不能用均值滤波,需要使用中值滤波
聚类算法: KMEANS:划分为K个族,K个质心,迭代:1.
将每个数据点分配给最近的邻居,2. 更新质心
KMEANS++(初始化一个质心,剩下的按照算法选择,而不是随机) 轮廓系数
高斯混合模型GMM聚类:基于概率的软聚类,假设数据由K个高斯分布表示,参数通过最大化似然估计获期望最大化优化。
层次聚类:自低向上,每次合并两个相邻类
KNN:分类或者回归。惰性、不适合高维数据、唯独灾难(维度增加,分类器性能下降,高维数据之间存在相似性,计算复杂,数据稀疏,过拟合)、计算量大,特征放缩敏感,建议标准化处理
PCA:PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。
https://mp.weixin.qq.com/s/_tCMU3LR9jKoQMybf0sUZA
EM算法:估计参数,E步计算期望,M步最大化
取对数:累加求和,求导方便。计算机精度表示不了太小 EM
算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含参数(EM
算法的 E
步),接着基于观察数据和猜测的隐含参数一起来极大化对数似然,求解我们的模型参数(EM算法的M步)。由于我们之前的隐含参数是猜测的,所以此时得到的模型参数一般还不是我们想要的结果。我们基于当前得到的模型参数,继续猜测隐含参数(EM算法的
E
步),然后继续极大化对数似然,求解我们的模型参数(EM算法的M步)。以此类推,不断的迭代下去,直到模型分布参数基本无变化,算法收敛,找到合适的模型参数。
一个最直观了解 EM 算法思路的是 K-Means 算法。在 K-Means
聚类时,每个聚类簇的质心是隐含数据。我们会假设 K 个初始化质心,即 EM
算法的 E
步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即 EM
算法的 M 步。重复这个 E 步和 M 步,直到质心不再变化为止,这样就完成了
K-Means 聚类。 E:计算联合分布的条件概率期望
M:极大化对数似然函数,得到参数,迭代到收敛
SVM算法:SVM则要找一个最优最优的划分超平面来将正负样本分开,要求不仅能将正负样本划分开来,而且距离超平面最近的样本点到超平面的距离尽可能大。
一些trick来解决线性不可分问题(除了核函数之外)?手动添加特征,
加大特征维度,使得线性可分
SVM没有处理缺失值的策略,而SVM希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失值影响训练结果的好坏。
目标检测
两阶段算法
生成式 判别式
对于输入x,类别标签y: 生成式模型估计它们的联合概率分布P(x,y)
判别式模型估计条件概率分布P(y|x)
HOG
方向梯度垂直直方图 物体检测的特征描述子 算法步骤: 1. 灰度化 2.
GAMMA归一化 调节对比度,降低局部阴影和光照变化的影响,抑制噪音的干扰 3.
计算 x,y 方向的梯度 4. 构建细胞单元 cell 的梯度方向直方图 5. Block
梯度强度归一化 6. 收集HOG特征 7.
特征维度数量取决于一个block内部有多少个cell和步长
SIFT
https://blog.csdn.net/Yong_Qi2015/article/details/121112750
LBP
八邻域比较,小于中心,标记1,否则0,8位二进制数作为LBP值。旋转不变性和灰度不变性,纹理特征提取。
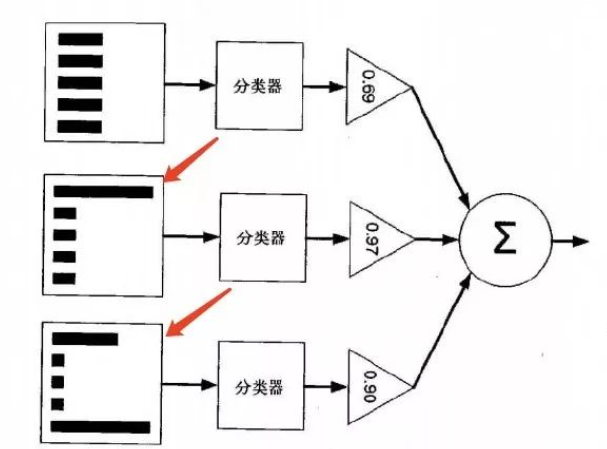
集成学习
https://mp.weixin.qq.com/s/uNQbSzMc7LzW7lbu1UCdIw
集成方法:投票选举(bagging: 自举汇聚法 bootstrap aggregating):
是基于数据随机重抽样分类器构造的方法再学习(boosting):
是基于所有分类器的加权求和的方法
目前 bagging 方法最流行的版本是: 随机森林(random forest)
选男友:美女选择择偶对象的时候,会问几个闺蜜的建议,最后选择一个综合得分最高的一个作为男朋友
目前 boosting 方法最流行的版本是: AdaBoost
追女友:3个帅哥追同一个美女,第1个帅哥失败->(传授经验:姓名、家庭情况)
第2个帅哥失败->(传授经验:兴趣爱好、性格特点) 第3个帅哥成功
bagging 和 boosting 区别是什么?bagging 是一种与 boosting
很类似的技术,
所使用的多个分类器的类型(数据量和特征量)都是一致的。bagging
是由不同的分类器(1.数据随机化
2.特征随机化)经过训练,综合得出的出现最多分类结果;boosting
是通过调整已有分类器错分的那些数据来获得新的分类器,得出目前最优的结果。bagging
中的分类器权重是相等的;而 boosting
中的分类器加权求和,所以权重并不相等,每个权重代表的是其对应分类器在上一轮迭代中的成功度。
随机森林 原理那随机森林具体如何构建呢? 有两个方面: 数据的随机性化
待选特征的随机化
AdaBoostAdaBoost (adaptive boosting: 自适应 boosting)
概述能否使用弱分类器和多个实例来构建一个强分类器?
alt text
级联分类器,将几个强分类器串联起来,逐层进入,前面通过才能进入后面
boosting 串行训练
adaboost 顺序训练的级联结构
每一轮迭代后更新样本权重和弱学习器权重(这里的弱学习器通常使用决策树桩,决策树桩是指一个单层决策树),从而实现整体性能的优化提升。核心逻辑在于
“前人栽树,后人乘凉”。即前辈为后辈创造条件,后辈在此基础上进行改进。在
AdaBoost
中,我们首先训练一个弱学习器,并对其预测性能进行评估。在每一轮迭代后,我们更新样本的权重,也就是改变样本的困难度。对预测正确的样本减少关注,而对预测错误的样本加大关注,使新模型更能专注于克服前面的模型无法正确预测的困难样本。
https://blog.csdn.net/IT_charge/article/details/120322875
https://mp.weixin.qq.com/s/J3zZdSuSsIdRQbStLMhTJA
https://mp.weixin.qq.com/s/Yk4T1HFpbokAxlc9odkFIw
1018 tplink 图像算法面试
自我介绍
CUB200项目中遇到了什么问题,欠拟合(预训练不能解决欠拟合,但是大模型可以)与过拟合怎么解决的
为什么你觉得模型攻击能解决过拟合问题,一般用于测试,但是加入到训练集中确实可以减弱过拟合。
PGD的计算方法
解决过拟合的方法
个性化搜索的细节,如何实现的,如何将dm应用到这个任务上面,如何构造训练的数据对
fixmatch 原理
transformer 计算方法
BN 层的计算方法,参数量,训练与推理时的区别。
1022 tplink 算法二面
自我介绍
多标签分类,标签缺失、类别不均衡
python 中 is 与 == 的区别
resnet 及其后续工作
详细询问CUB200项目,方法等等,数据增强
梯度消失与梯度爆炸
增大感受野的方法,空洞卷积、增大核面积
diffusion model 项目的原理与工作
复杂场景下的行人识别???
fixmatch 标签?
有没有关注最新的工作进展?
Git 如何解决冲突,还需要 commit吗?